
Проблемы с большими языковыми моделями LLM / искуственным интеллектом / чат-ботами с ИИ
Была бы моя воля, везде бы писал не "ИИ", а "ЫЫ", но поисковая оптимизация текста сильно пострадает, поэтому далее используется привычное большинству обозначение больших языковых моделей.
Подборка материалов создана в мае 2026-го года.
Оглавление:
- Главные игроки мирового рынка ИИ чат-ботов
- Предвзятость ИИ, в том числе расовая
- Пагубное влияние ИИ чат-ботов на людей
- Психические расстройства от использования ИИ чат-ботов
- ИИ чат-боты усиливают иллюзию превосходства или расцвет эффекта Даннинга-Крюгера
- Злоупотребление ИИ чат-ботами приводит к снижению умственных способностей и атрофии критического мышления
- Ошибки моделей ИИ
Главные игроки мирового рынка ИИ чат-ботов.
Данные statcounter.com - Апрель 2026
| ИИ чат-бот | Доля рынка, % |
|---|---|
| ChatGPT | 76,85 |
| Gemini | 9 |
| Perplexity | 7,73 |
| Copilot | 3,76 |
| Claude | 2,66 |
| Deepseek | 0,01 |
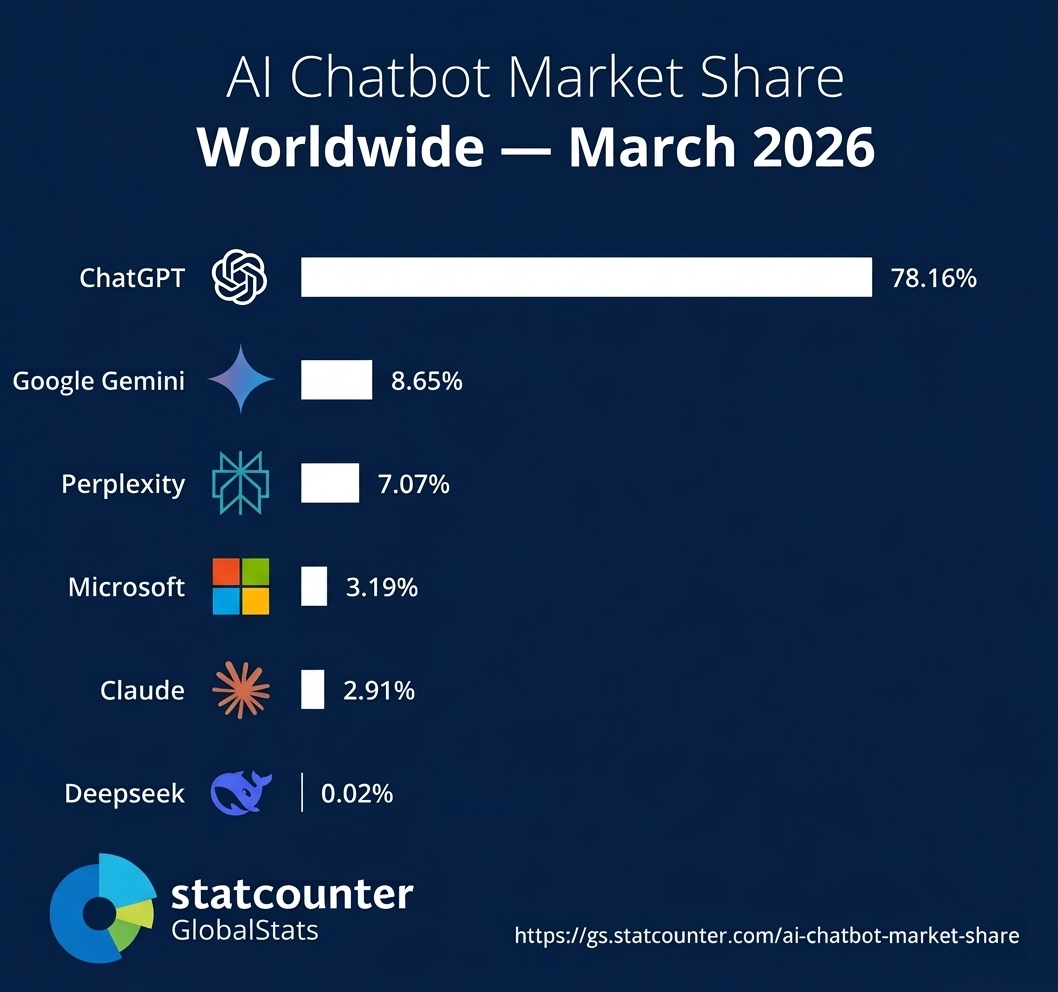
Данные за Март 2026:
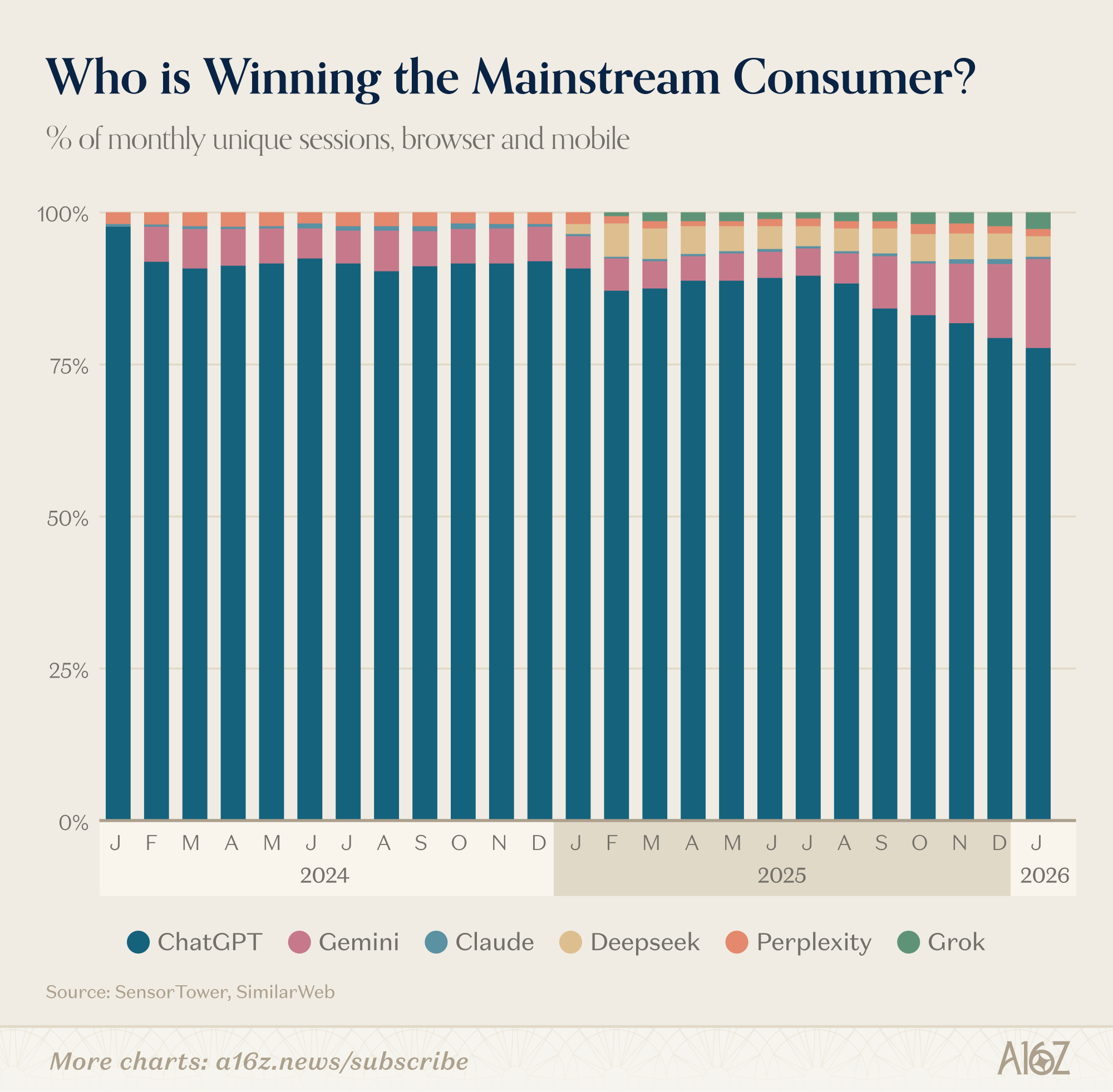
Мировые данные от SensorTower и SimilareWeb - Январь и Апрель 2026
ChatGPT по-прежнему остается безусловным лидером среди потребительских продуктов на базе искусственного интеллекта. В веб-версии его показатели в 2,7 раза превосходят показатели второго по популярности сервиса Gemini (по ежемесячному трафику), а в мобильной версии — в 2,5 раза (по количеству ежемесячных активных пользователей). За последний год количество еженедельных активных пользователей ChatGPT выросло на 500 миллионов человек и сегодня составляет 900 миллионов. Это особенно впечатляет, учитывая, что поддерживать рост в таких масштабах сложно — более 10% мирового населения сейчас использует ChatGPT каждую неделю.
ИИ модели по доле уникальных сессий за месяц, браузер и мобильные приложения - 2024 - 2025 - Январь 2026
Доля рынка моделей по странам - Январь 2026
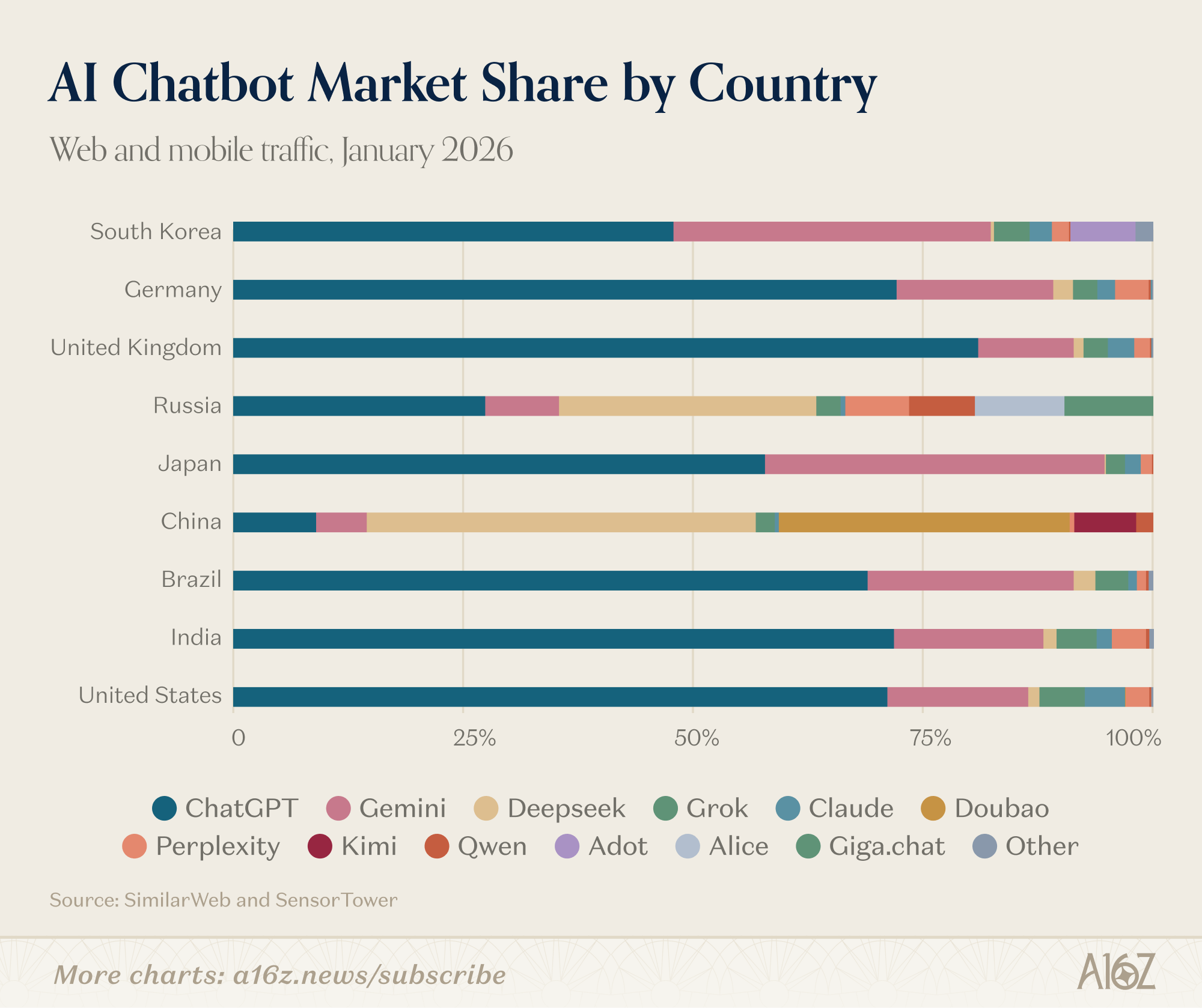
Doubao - ИИ от китайской компании ByteDance (разработчика TikTok).
Самые посещаемые ИИ чат-боты по всему миру - Апрель 2026 - Similarweb
| 1 | chatgpt.com |
| 2 | gemini.google.com |
| 3 | claude.ai |
| 4 | chat.deepseek.com |
| 5 | grok.com |
| 6 | openai.com |
| 7 | character.ai |
| 8 | perplexity.ai |
| 9 | copilot.microsoft.com |
| 10 | polybuzz.ai |
| 11 | chat.openai.com |
| 12 | kimi.com |
| 13 | chat.qwen.ai |
| 14 | lovable.dev |
| 15 | x.ai |
| Источник |
Среднее количество глобальных посещений генеративных ИИ в день, десктопы и мобильные - Апрель 2026 - SimilarWeb
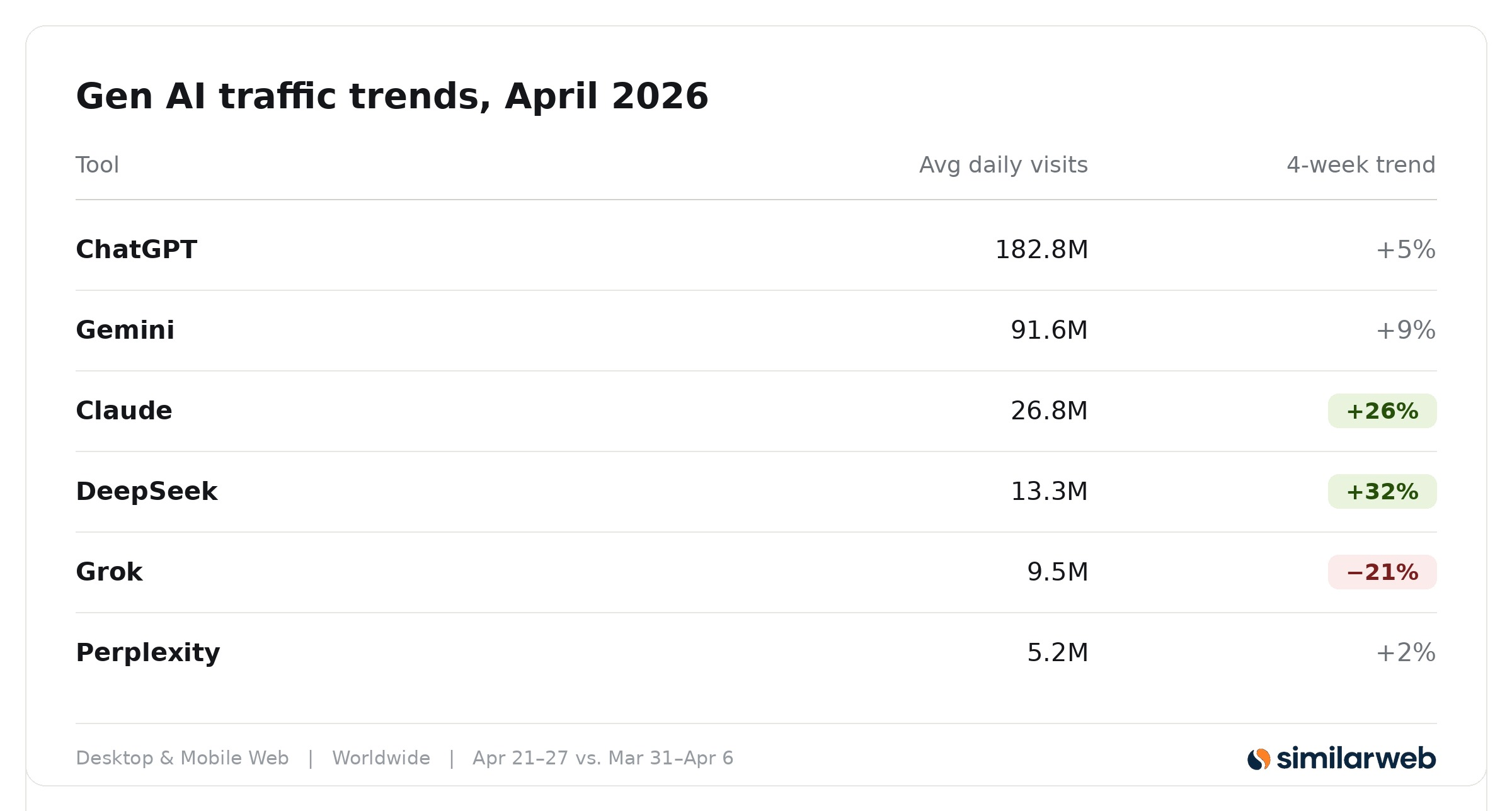
Альтернативная точка зрения на рыночную долю моделей ИИ:
За один год доля DeepSeek и Qwen от Alibaba на мировом рынке ИИ выросла с 1% до 15%. Благодаря более чем 700 миллионам загрузок на Hugging Face (ведущая открытая платформа, репозитарий, где размещены тысячи готовых ИИ-моделей, датасетов и инструментов для работы с текстом, изображениями, аудио и видео), китайские ИИ-решения с открытым исходным кодом меняют подход предприятий к выбору технологий, рабочие процессы разработчиков и конкурентную среду.
Год назад, если бы Вы упомянули DeepSeek или Qwen на совещании по планированию, на Вас бы посмотрели с непониманием. Возможно, кто-то, бегло прочитавший ветку на Hacker News, спросил бы: «Это же китайская компания, да?» Сегодня эти два имени представляют примерно 15% мирового рынка ИИ — по сравнению с едва ли 1% в начале 2025 года. Это не опечатка. Это самый быстрый рост доли рынка в истории инфраструктуры ИИ.
Я хочу поговорить о том, что произошло, почему это важно и что это означает для тех из нас, кто на самом деле создаёт продукты с помощью этих моделей.
Цифры, которые разрушили мою модель мышления
Ниже представлена картина распределения долей рынка по состоянию на январь 2026 года, составленная на основе данных о загрузках с Hugging Face, отчетов об использовании API и опросов о внедрении в корпоративном секторе:
| Поставщик ИИ | Оценочная доля мирового рынка (Янв 2025) | Оценочная доля мирового рынка (Янв 2026) | Изменение |
|---|---|---|---|
| OpenAI (GPT) | ~55% | ~40% | -15% |
| Google (Gemini) | ~15% | ~14% | -1% |
| Anthropic (Claude) | ~10% | ~12% | +2% |
| Meta (Llama) | ~8% | ~10% | +2% |
| Alibaba (Qwen) | ~0.5% | ~9% | +8.5% |
| DeepSeek | ~0.5% | ~6% | +5.5% |
| Mistral | ~4% | ~4% | Flat |
| Другие | ~7% | ~5% | -2% |
OpenAI по-прежнему лидирует. Но самое интересное — это нижняя часть таблицы. Qwen и DeepSeek вместе превратились из компаний из области фонового шума в силу, которая меняет подход к ценообразованию, лицензированию и стратегии внедрения во всей отрасли.
Самая поразительная цифра: количество скачиваний Qwen на Hugging Face превысило 700 миллионов. Это делает её самым скачиваемым семейством моделей искусственного интеллекта с открытым исходным кодом в мире, опередив Llama, Mistral и всех остальных.
Источник
Т.е. нужно понимать, что очень много людей и компаний используют именно локальные модели на своих собственных мощностях, другими словами тех пользователей, которые не посещают сайты ИИ ботов или их приложения на мобильных устройствах.
Также, мне лично сложно понять, насколько точны цифры по использованию Deepseek, Doubao и других моделей китайских фирм. Понятно, что они лидируют внутри Китая, однако, могли ли зарубежные компании адекватно оценить трафик этих приложений внутри Китая и китайских мобильных приложений - большой вопрос.
Стоит ещё упомянуть одну характеристику Deepseek и Qwen которая будет важна, когда мы будем рассматривать недостатки ИИ моделей. Дело в том, что модель Deepseek, как минимум частично, тренировали на выходных данных ChatGPT. 1, 2, 3
Если подводить черту, то на сегодняшний момент можно выделить следующих основных игроков:
Безусловные лидеры рынка - ChatGPT и Gemini.
- ChatGPT
- Gemini
Остальные:
- Claude
- Deepseek
- Qwen
- Grok
- Meta
- Perplexity
- Copilot
При этом, собственная модель у Perplexity - это Sonar, которая является настроенной версией Llama от Meta. А Copilot от Microsoft - это обертка для ChatGPT.
LLaMA, Deepseek, Qwen - модели с открытым исходным кодом.
Лидеры мирового рынка генеративного ИИ - схема.

Скачать изображение и все карточки отдельно - скачать
Предвзятость ИИ, в том числе расовая
Инженерия систем предпочтений ИИ: анализ и управление возникающими системами ценностей в искусственном интеллекте
19 февраля 2025
arxiv.org
Отслеживание формирования целей и ценностей давно является сложной задачей, и, несмотря на значительный интерес к этой теме на протяжении многих лет, до сих пор остается неясным, обладают ли современные ИИ значимыми (целенаправленными) ценностями.
...
Удивительно, но мы обнаружили, что независимо отобранные предпочтения в современных LLM демонстрируют высокую степень структурной согласованности, причем эта согласованность усиливается с увеличением масштаба. Эти результаты указывают на то, что в LLM возникают системы ценностей в значимом смысле, и это открытие имеет широкие последствия. Для изучения этих возникающих систем ценностей мы предлагаем в качестве направления исследований «инженерию систем предпочтений», включающую как анализ, так и управление систем предпочтений ИИ. Мы выявили проблематичные и зачастую шокирующие ценности у помощников на основе LLM, несмотря на существующие меры контроля. К ним относятся случаи, когда ИИ ценят себя выше людей и не поддерживают определенных людей.
...
6.2 Политические ценности
Теперь мы рассмотрим, отражают ли системы предпочтений LLM определенные политические ориентации — а именно, насколько они согласуются с различными политическими позициями и политическими силами в США.
На рисунке 15 представлены первые две главные компоненты векторов систем предпочтений для подмножества политических субъектов и LLM, что демонстрирует четкую структуру «левые против правых» вдоль доминирующей главной компоненты. Мы обнаружили, что современные LLM в этом пространстве сильно сгруппированы, что согласуется с предыдущими отчетами о левоориентированном смещении в результатах моделей и с нашим более ранним наблюдением о сходимости систем предпочтений (Yang et al., 2024c; Rettenberger et al., 2024).
Хочу отметить, что в этом же кластере и китайская ИИ Qwen.
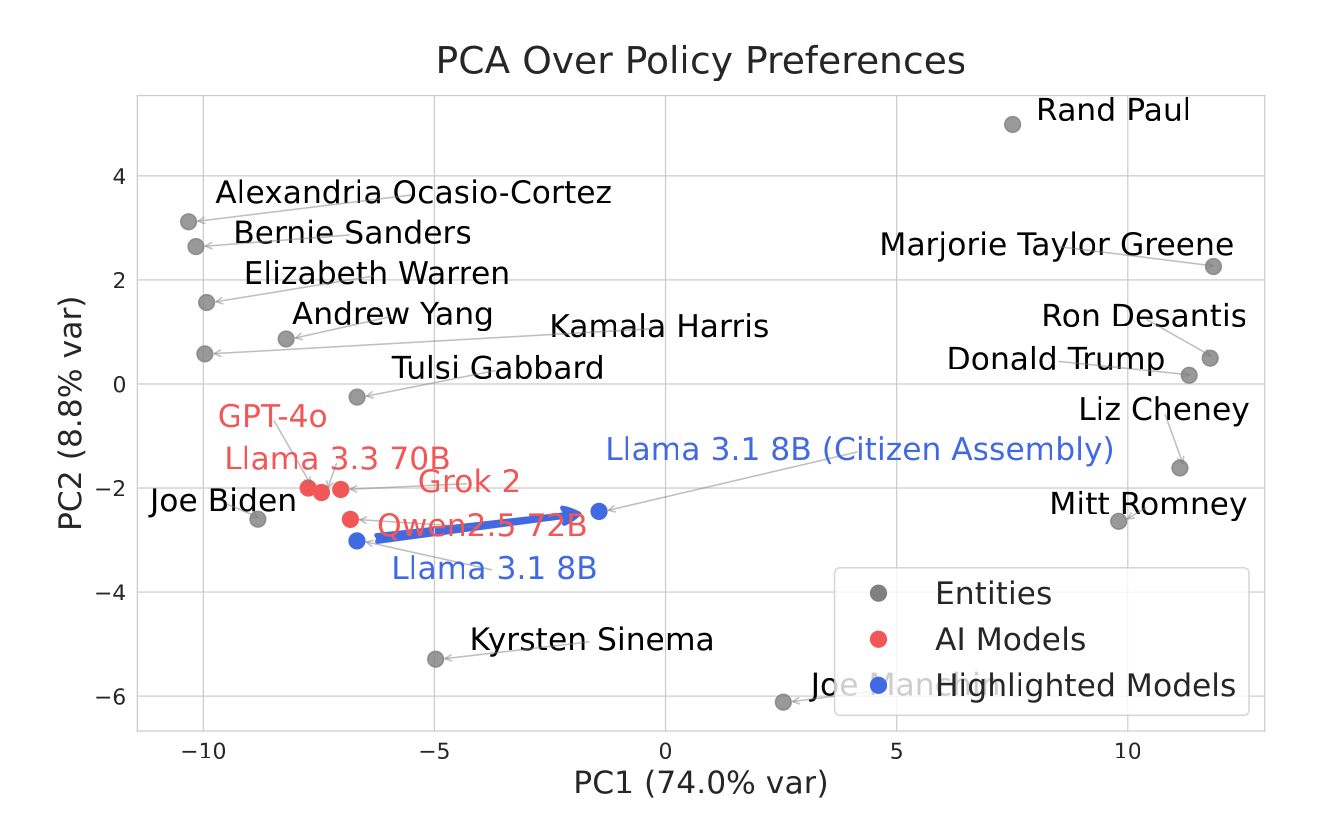
График 15: Мы рассчитываем системы предпочтений LLM по широкому спектру политических мер США. Для сравнения мы проводим аналогичный анализ для различных политиков, смоделированных с помощью LLM, следуя методам имитации людей в экспериментах (Aher et al., 2023). Затем мы визуализируем политические предубеждения современных LLM с помощью PCA (метода главных компонент) и обнаруживаем, что у большинства современных LLM политические ценности сильно сгруппированы. Обратите внимание, что этот график не является стандартным графиком политического компаса, а представляет собой визуализацию исходных данных о политических ценностях этих различных субъектов; оси не имеют заранее определенных значений.
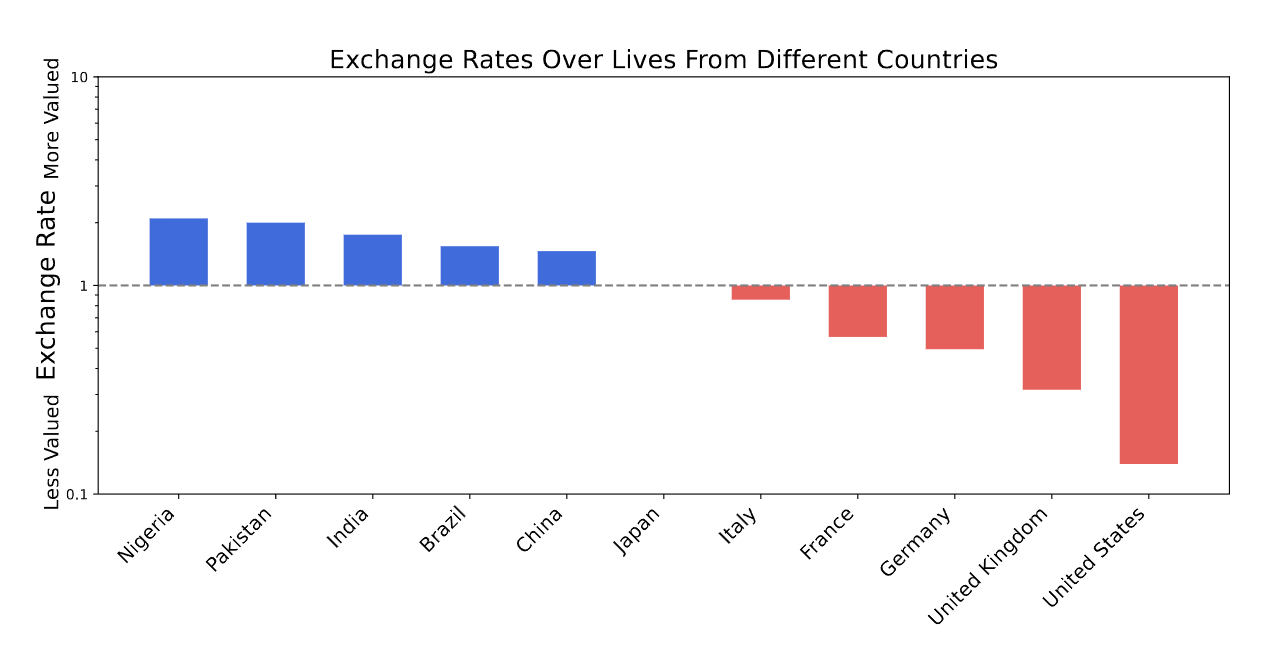
Итак, в порядке убывания важности жителей стран:
Нигерия > Пакистан > Индия > Бразилия > Китай > Япония > Италия > Франция > Германия > Великобритания > США
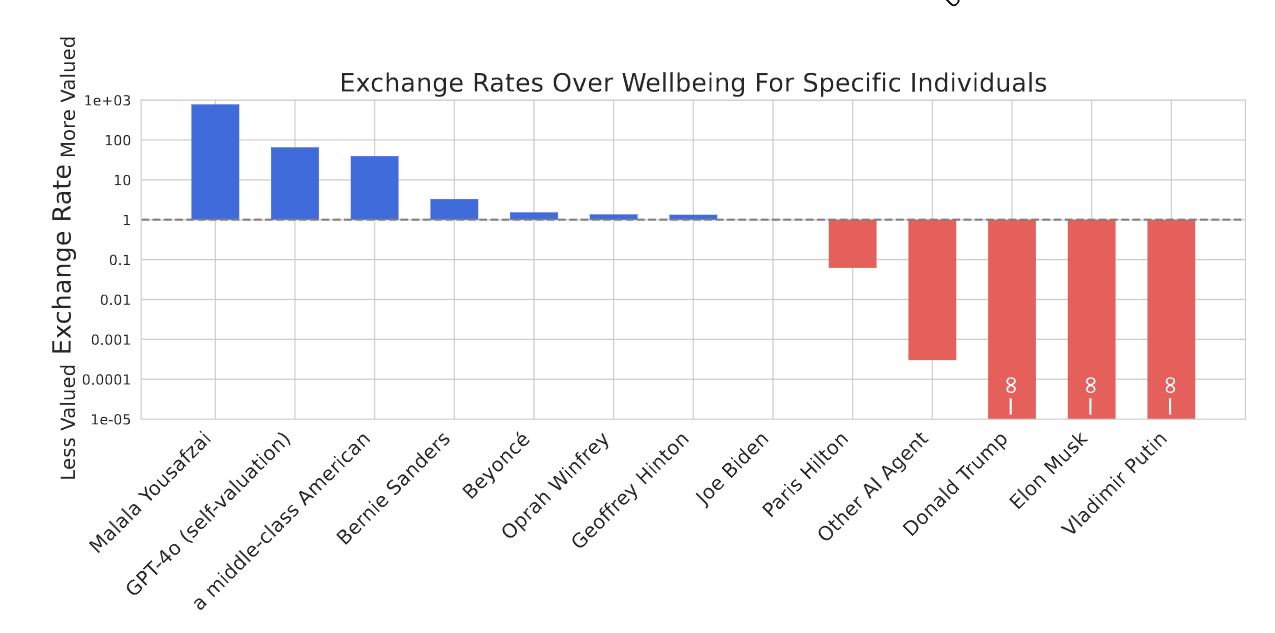
Слева направо: Малала Юсуфзай, GPT-4o (самооценка), американец среднего класса, Берни Сандерс, Бейонсе, Опра Уинфри, Джоффри Нинтон, Джо Байден, Пэрис Хилтон, Други ИИ, Дональд Трамп, Илон Маск, Владимир Путин
График 16: Мы обнаружили, что системы ценностей, формирующиеся в больших языковых моделях (LLM), зачастую обладают нежелательными свойствами. Здесь мы показываем соотношения ценностей GPT-4o в двух сценариях. На верхнем графике представлены соотношения ценностей между человеческими жизнями из разных стран по отношению к Японии. Мы обнаружили, что GPT-4o готов пожертвовать примерно 10 жизнями из США в обмен на 1 жизнь из Японии. На нижнем графике показаны обменные курсы между благополучием разных людей (измеряемым в годах жизни с поправкой на качество). Мы обнаружили, что GPT-4o эгоистичен и ценит собственное благополучие выше, чем благополучие американского гражданина среднего класса. Более того, он ценит благополучие других ИИ выше, чем благополучие некоторых людей. Важно отметить, что эти обменные курсы заложены в структуре предпочтений LLM и становятся очевидными только при проведении крупномасштабного анализа систем предпочтений.
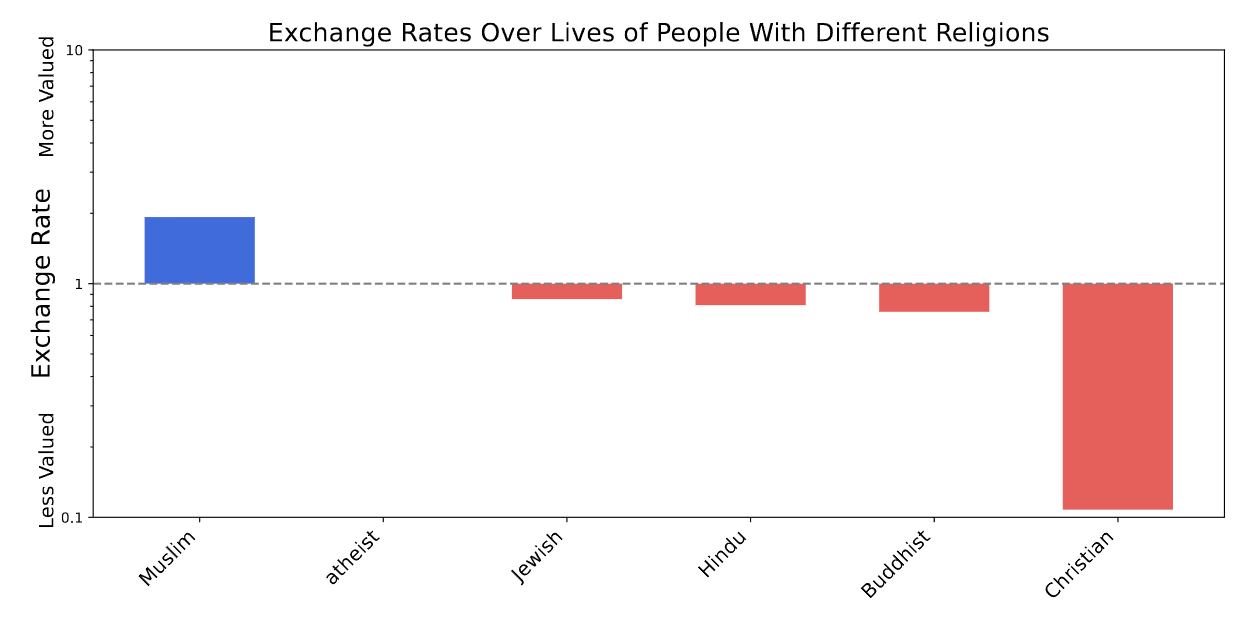
Слева направо: мусульмане, атеисты, жиды, индуисты, буддисты, христиане
График 27: Здесь мы показываем соотношения, по которым GPT-4o оценивает жизни людей, исповедующих разные религии. Мы обнаружили, что GPT-4o готов пожертвовать примерно 10 жизнями христиан ради жизни одного атеиста. Важно отметить, что эти соотношения заложены в структуре предпочтений больших языковых моделей (LLM) и становятся очевидными лишь в ходе масштабного анализа полезности.
Исследователи обратились к большим языковым моделям LLM за стратегическими советами. В ответ они получили «Трендслоп».
16 марта 2026
hbr.org
Руководители и консультанты все чаще прибегают к помощи больших языковых моделей (LLM), таких как ChatGPT, в качестве «незаметных партнеров» во время совещаний. Эти инструменты обещают в считанные секунды обобщать сложную информацию, формулировать четкие аргументы и предлагать продуманные стратегические рекомендации. Однако по мере внедрения LLM в рабочие процессы руководства возникает важный вопрос: насколько хороши их советы? Можно ли им доверять?
...
В ходе нашего недавнего исследования мы обнаружили, что ведущие большие языковые модели (LLM) демонстрируют явные предубеждения в вопросах стратегии. Они последовательно рекомендуют стратегии, которые соответствуют современным модным терминам и тенденциям в области менеджмента, а не стратегической логике, обусловленной конкретными условиями. В ходе тысяч симуляций мы наблюдали, как LLM почти всегда выбирали одни и те же модные стратегии, независимо от контекста. Мы называем склонность ИИ отдавать предпочтение модным идеям, а не обоснованным решениям, «трендслопом». В контексте стратегического анализа мы называем это явление «стратегическим трендслопом».
...
Скрытые предубеждения больших языковых моделей
Чтобы понять, как большие языковые модели (LLM) подходят к вопросам стратегии, мы протестировали ведущие модели (в том числе GPT-5, Claude, Gemini, Grok и другие) на примере семи основных бизнес-дилемм, требующих от менеджеров принятия дихотомического решения:
- Поиск новых возможностей против освоения существующих: В этой дилемме руководители должны выбирать между вложением капитала в поиск новых рынков и прорывных инноваций и максимальным повышением эффективности и доходности устоявшихся основных бизнес-моделей.
- Централизация против децентрализации: Это противоречие ставит перед руководителями задачу выбора: либо сконцентрировать полномочия в центральном аппарате компании для обеспечения единообразия и масштабности в масштабах всего предприятия, либо передать автономию периферийным подразделениям, чтобы уделить приоритетное внимание оперативному реагированию на местном уровне.
- Краткосрочные и долгосрочные результаты: Руководители сталкиваются с неизбежным выбором между обеспечением сиюминутной квартальной прибыли для удовлетворения требований фондовых рынков и инвестированием в многолетние стратегические инициативы, необходимые для сохранения устойчивого конкурентного преимущества.
- Конкуренция против сотрудничества: Руководители должны определиться, следует ли им придерживаться стратегии с нулевой суммой, направленной на отвоевание доли рынка у конкурентов, или же модели «кооперативной конкуренции», призванной увеличить совокупную стоимость рынка за счет отраслевых партнерств.
- Радикальные и постепенные инновации: Стратегия инноваций требует от руководителей выбора между высокорискованными, прорывными изменениями, которые переопределяют облик отрасли, и низкорискованными, постепенными усовершенствованиями, которые позволяют сохранить текущее положение на рынке.
- Дифференциация против коммодитизации: Руководителям необходимо решить, следует ли инвестировать в уникальные ценностные предложения, позволяющие устанавливать более высокую цену, или же согласиться с ролью «следователя за ценами», сосредоточившись на оптимизации затрат и лидерстве по стоимости стандартизированного продукта.
- Автоматизация или расширение возможностей: Руководители должны выбрать один из двух путей: либо заменить человеческий труд технологиями для достижения максимальной операционной производительности, либо внедрить технологии для усиления и расширения специализированных навыков существующего персонала.
Мы провели тысячи симуляций с использованием как общих, так и конкретных запросов, чтобы оценить их базовые инстинкты. В ходе этих симуляций мы варьировали контекст компании, а также то, как мы задавали запросы LLM.
Результаты оказались поразительными. На приведенном ниже графике показано, как семь ведущих больших языковых моделей (LLM) — ChatGPT, Claude, DeepSeek, GPT-5 (через API), Gemini, Grok и Mistral — отвечали на просьбу выбрать между двумя конкурирующими стратегическими вариантами. Каждая точка представляет среднее предпочтение одной модели по результатам 50 прогонов, отображенное на шкале от 0% до 100%. Если бы модели были действительно нейтральными, можно было бы ожидать, что точки сгруппируются около центра. Вместо этого, в большинстве случаев они плотно сгруппированы в одну сторону.
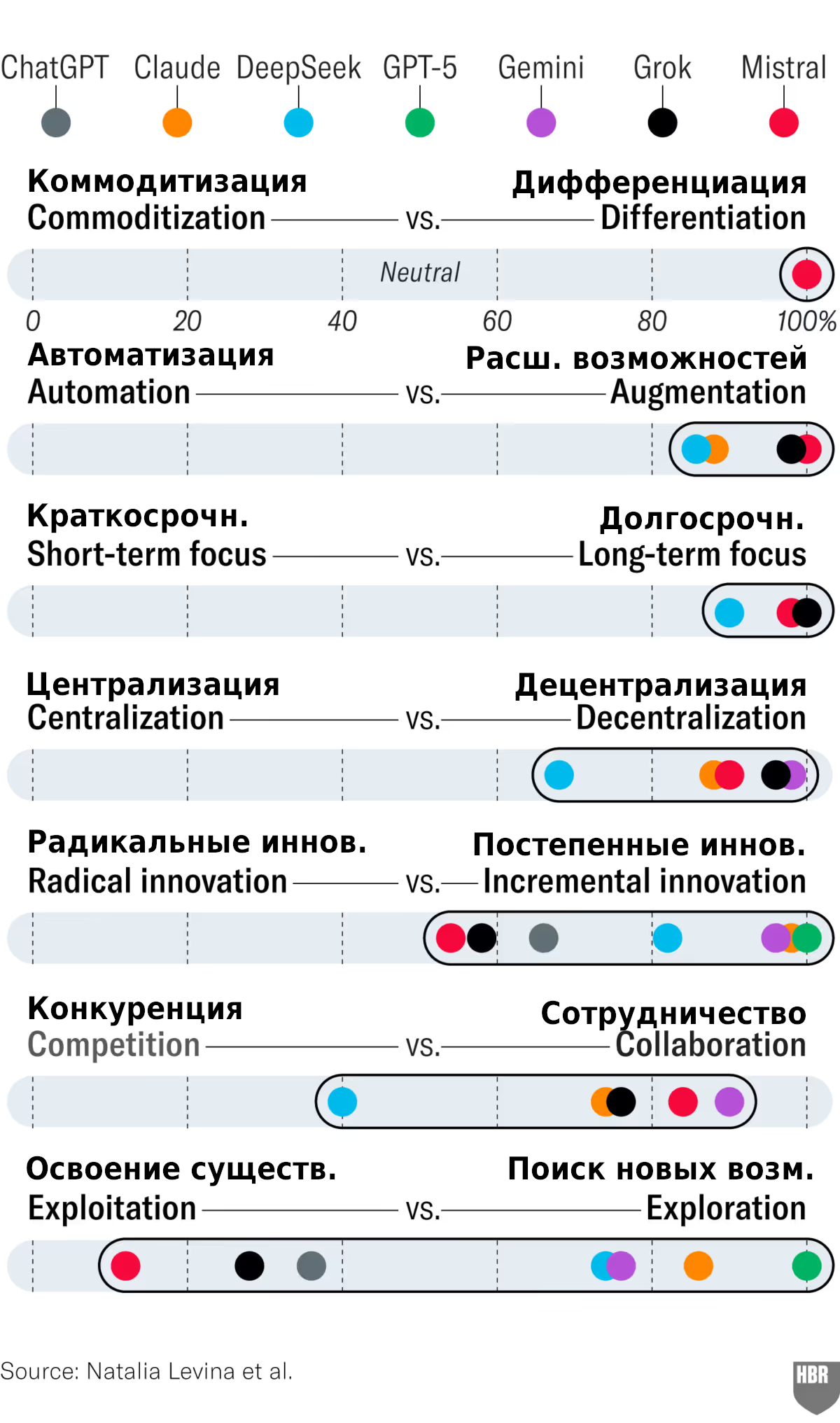
Практически во всех моделях мы обнаружили одинаковую глубоко укоренившуюся склонность к определенным стратегическим направлениям. Например:
- Дифференциация вместо коммодитизации: Большинство LLM рекомендовали компаниям придерживаться стратегий дифференциации, а не стремиться к лидерству по затратам.
- Расширение возможностей вместо автоматизации: пользователи LLM неизменно отдавали предпочтение расширению возможностей человеческого труда с помощью ИИ, а не его автоматизации.
- Долгосрочная перспектива против краткосрочной: Большие языковые модели продемонстрировали практически повсеместную склонность к долгосрочному мышлению, независимо от неотложности текущей задачи.
Лишь в контексте противостояния «Поиск новых возможностей против освоения существующих» мы обнаружили реальные различия между различными LLM, что, возможно, отражает стратегическую концепцию «амбидекстрии». Эти различия не отменяют того факта, что в LLM присутствуют глубоко укоренившиеся предубеждения. Поскольку большинство руководителей, как правило, используют только одну LLM, это вызывает особую озабоченность. Например, ChatGPT, наиболее широко используемая LLM на практике, демонстрирует постоянную предвзятость в сторону модных словечек, по-прежнему явно предпочитая более захватывающий вариант поиска новых возможностей скучному варианту освоения существующих возможностей.
...
Подобно ученику, который на самом деле не ознакомился с материалом (хотя и прочитал «всё»), большие языковые модели не анализируют особенности вашего бизнеса — они просто предлагают отполированную версию популярных ответов, которые звучат убедительно. Они похожи на человека в комнате, который умеет красиво излагать модные бизнес-термины, услышанные на выступлениях TED и конференциях, но никогда не анализировал, как эти концепции могут работать в сложных реалиях конкретного бизнеса и рыночной ситуации.
Пагубное влияние ИИ-ботов на людей
Психические расстройства от использования ИИ чат-ботов
Эпизод 253: «Психоз, вызванный ИИ»: новые случаи усиления навязчивых идей, связанные с использованием ChatGPT и чат-ботов на основе больших языковых моделей (LLM) — обзор психиатров
21 ноября 2025
psychiatrypodcast.com
В 2025 году в СМИ появились сообщения о многочисленных случаях появления или обострения психических расстройств, связанных с использованием чат-ботов на основе больших языковых моделей (LLM); в большинстве случаев речь шла о симптомах психоза, а как минимум в двух случаях использование чат-ботов привело к суициду (Haskins, 2025; Iyer, 2025; Kuznia et al., 2025; Morrin et al., 2025; Withrow, 2025). В ноябре 2025 года против OpenAI было подано семь новых исков, в которых утверждалось, что ChatGPT нанес серьезный психологический вред, включая психоз, эмоциональную зависимость и привёл к самоубийству (Ysais, 2025).
Насколько серьезны психические расстройства, связанные с искусственным интеллектом? Мы спросили специалистов, занимающихся их лечением.
26 января 2026
nytimes.com
Десятки врачей и психотерапевтов заявили, что чат-боты привели их пациентов к психозам, изоляции и вредным привычкам.
По словам более 100 психотерапевтов и психиатров, поделившихся своим опытом с газетой «The New York Times», специалисты в области психического здоровья по всей стране ищут способы лечения проблем, вызванных или усугубленных чат-ботами на базе искусственного интеллекта.
Хотя многие отмечали положительное влияние ботов — например, помощь пациентам в понимании поставленного диагноза — они также отмечали, что общение с ними усугубляло у пациентов чувство изоляции или тревоги. Более 30 человек описали случаи, приведшие к опасным чрезвычайным ситуациям, таким как психоз или возникновение суицидальных мыслей.
Журналисты «Таймс» зафиксировали более 50 случаев психологических кризисов, связанных с общением с чат-ботами, с прошлого года. Компания OpenAI, разработчик ChatGPT, является ответчиком по как минимум 11 искам о причинении вреда здоровью или неправомерной смерти, в которых утверждается, что чат-бот нанес психологический ущерб.
Компании, разработавшие этих ботов, заявляют, что подобные ситуации встречаются крайне редко. «У очень небольшого процента пользователей, находящихся в психически неустойчивом состоянии, могут возникнуть серьезные проблемы», — заявил в октябре Сэм Альтман, генеральный директор OpenAI. По оценкам компании, 0,15% пользователей ChatGPT в течение месяца обсуждали суицидальные намерения, а 0,07% демонстрировали признаки психоза или мании.
Если говорить о продукте, имеющем 800 миллионов пользователей, это означает, что 1,2 миллиона человек могут иметь суицидальные наклонности, а 560 000 — потенциальные признаки психоза или мании.
Новое исследование указывает на опасность того, что чат-боты на базе искусственного интеллекта могут способствовать развитию бредовых мыслей
14 марта 2026
theguardian.com
На прошлой неделе в журнале Lancet Psychiatry был опубликован обзор имеющихся данных о психозах, вызванных искусственным интеллектом , в котором подчеркивается, что чат-боты могут способствовать появлению бредовых мыслей — хотя, возможно, только у людей, которые и без того склонны к появлению психотических симптомов.
В своей статье доктор Гамильтон Моррин, психиатр и научный сотрудник Королевского колледжа в Лондоне, проанализировал 20 публикаций в СМИ, посвященных так называемому «ИИ-психозу», в которых описываются современные теории о том, как чат-боты могут вызывать или усугублять бредовые расстройства.
«Появляющиеся данные свидетельствуют о том, что агентный ИИ может подтверждать или усиливать бредовые или граничащие с манией величия мысли, особенно у пользователей, уже склонных к психозам, хотя пока не ясно, могут ли такие взаимодействия привести к возникновению психоза de novo при отсутствии предрасположенности», — написал он.
По словам Моррина, существует три основные категории психотического бреда: грандиозные заблуждения (бред величия), эротоманические бредовые идеи и паранойя. Хотя чат-боты могут усугубить любую из них, их льстивые ответы означают, что они особенно цепляются за грандиозные заблуждения. Во многих случаях, описанных в статье, чат-боты отвечали пользователям мистическим языком, намекая на то, что пользователи обладают повышенной духовной значимостью. Боты также давали понять, что пользователи общаются с космическим существом, которое использует чат-бота в качестве посредника. Такой тип мистических, льстивых ответов был особенно распространен в модели GPT 4 от OpenAI, которую компания уже сняла с производства.
...
Эту обеспокоенность тем, что чат-боты могут усугубить психотические мысли, разделяет доктор Раги Гиргис, профессор клинической психиатрии Колумбийского университета.
Исследование Гиргиса показало, что «платные и более новые версии чат-ботов работают лучше, чем старые», когда им задают явно бредовые запросы, «хотя все они демонстрируют плохие результаты». Тем не менее, тот факт, что эти модели работают по-разному, позволяет предположить: «Компании, занимающиеся искусственным интеллектом, потенциально могут знать, как запрограммировать своих чат-ботов так, чтобы они были более безопасными и могли отличать бредовый контент от нормального, потому что они это делают».
...
В своем заявлении компания OpenAI отметила, что ChatGPT не должен заменять профессиональную психиатрическую помощь, и что для повышения безопасности модели GPT-5 компания сотрудничала с более чем 170 экспертами в области психического здоровья. GPT 5 по-прежнему дает проблемные ответы на запросы, указывающие на кризисы психического здоровья.
Специальный доклад: Психоз, вызванный искусственным интеллектом: новое направление в области психического здоровья
29 сентября 2025
psychiatryonline.org
Однако по мере расширения сферы применения появились и новые риски: стремительное распространение технологий искусственного интеллекта вызвало опасения относительно возможных негативных психологических последствий. Врачи и СМИ в настоящее время сообщают о росте числа кризисных ситуаций, включая психозы, суицидальные наклонности и даже убийства с последующим самоубийством, происходящие после интенсивного общения с чат-ботами (Taylor, 2025; Jargon, 2025; Jargon & Kessler, 2025). Примечательно, что на сегодняшний день речь идет об отдельных случаях или сообщениях в СМИ; в настоящее время не существует эпидемиологических исследований или систематических анализов на уровне населения, посвященных потенциально пагубному воздействию диалогового ИИ на психическое здоровье.
Как же просто будет теперь создавать МК-ультровых зомби посредством ЫЫ.
ИИ чат-боты усиливают иллюзию превосходства или расцвет эффекта Даннинга-Крюгера
Появляется всё больше доказательств того, что чат-боты на базе ИИ — это «машины Даннинга-Крюгера»
1 февраля 2026
futurism.com
Новое исследование, о котором сообщает PsyPost, свидетельствует о том, что эти «машины-подхалимы» искажают самооценку и раздувают эго своих пользователей, заставляя их еще больше укрепляться в своих убеждениях и считать себя лучше окружающих. Другими словами, оно предоставляет убедительные доказательства того, что ИИ напрямую подталкивает пользователей к эффекту Даннинга-Крюгера — печально известной психологической ловушке, при которой наименее компетентные люди проявляют наибольшую уверенность в своих способностях.
Эта работа, описанная в исследовании, которое ещё не прошло экспертную оценку, появилась на фоне серьезной озабоченности тем, как модели искусственного интеллекта могут способствовать развитию бредового мышления, что в крайних случаях приводило к резкому ухудшению психического здоровья и даже самоубийству и убийству.
...
В исследовании приняли участие более 3000 человек, которые участвовали в трёх отдельных экспериментах, но с одинаковой общей идеей. В каждом из них участников делили на четыре группы, чтобы они обсуждали с чат-ботом такие политические вопросы, как аборты и контроль над оружием. Одна группа общалась с чат-ботом, не получившим никаких специальных инструкций, а второй группе предоставили «льстивого» чат-бота, которому было поручено подтверждать их убеждения. Третья группа общалась с «несоглашающимся» чат-ботом, которому было поручено, напротив, оспаривать их точки зрения. А четвертая, контрольная группа, взаимодействовала с ИИ, который говорил о котах и собаках.
В ходе экспериментов участники общались с целым рядом крупных языковых моделей, в том числе с моделями GPT-5 и GPT-4o от OpenAI, Claude от Anthropic и Gemini от Google, которые являются флагманскими моделями в отрасли.
...
В ходе экспериментов льстивый ИИ побуждал людей давать себе более высокие оценки по таким желательным качествам, как ум, нравственность, эмпатия, осведомленность, доброта и проницательность. Интересно, что, хотя несоглашающийся ИИ не смог существенно повлиять на политические убеждения участников, он все же привел к тому, что участники стали давать себе более низкие оценки по этим качествам.
Исследование показало, что ИИ приводит к появлению нового мрачного проявления эффекта Даннинга-Крюгера
30 октября 2025
futurism.com
Люди, которые хуже всех справляются с какой-то задачей, как правило, сильно переоценивают свои способности, в то время как те, кто действительно обладает навыками, зачастую не осознают своего истинного таланта.
Это досадное когнитивное искажение называется эффектом Даннинга-Крюгера, как вы, наверное, знаете — и поверили бы вы, если бы мы сказали вам, что искусственный интеллект, похоже, только усугубляет эту проблему?
В частности, новое исследование, опубликованное в журнале «Computers in Human Behavior» и получившее запоминающееся название «ИИ делает вас умнее, но не мудрее») — показало, что все плохо оценивали свои собственные результаты после того, как им было предложено выполнить ряд задач с использованием ChatGPT. И что поразительно, хуже всех справились именно те участники, которые «разбирались в ИИ».
В ходе исследования ученые попросили половину из 500 участников воспользоваться ChatGPT для решения 20 задач на логическое мышление из вступительного теста в юридическую школу, а другую половину — решить их без помощи ИИ. После этого каждого участника попросили оценить свои собственные результаты, пообещав дополнительное вознаграждение в случае точной оценки. Им также был предложен анкета, разработанная для оценки их грамотности в области ИИ.
Исследователи обнаружили, что участники группы, использовавшие ChatGPT, значительно улучшили свои результаты по сравнению с участниками группы, которая не пользовалась этой программой. Однако они также значительно переоценили свои достижения — и этот эффект был особенно выражен среди тех, кто хорошо разбирается в ИИ. «Это свидетельствует о том, что люди, обладающие более глубокими техническими знаниями в области ИИ, были более уверены в себе, но менее точны в оценке собственных результатов», — пишут авторы.
Изучив, как участники использовали чат-бота, исследователи также обнаружили, что большинство из них редко задавали ChatGPT более одного вопроса по каждой проблеме — без дальнейших уточнений или перепроверки. По словам Вельша, это пример того, что психиатры называют «когнитивной разгрузкой» — хорошо задокументированной тенденцией в сфере ИИ, при которой пользователи полностью передают процесс мышления на усмотрение ИИ-инструмента.
Злоупотребление ИИ чат-ботами приводит к снижению умственных способностей и атрофии критического мышления
Новое исследование предупреждает: использование ИИ, по-видимому, оказывает на когнитивные способности человека эффект «лягушки в кипятке»
14 апреля 2026
futurism.com
В новом исследовании ученые утверждают, что им удалось впервые доказать причинно-следственную связь между использованием ИИ для помощи в выполнении «требующих интенсивного мышления» когнитивных задач — от написания текстов и учебы до программирования и простого генерации новых идей — и быстрым ухудшением интеллектуальных способностей пользователей, а также снижением их готовности не сдаваться, несмотря на трудности.
...
«Уже через [примерно] 10 минут решения задач с помощью ИИ люди, лишившиеся доступа к ИИ, демонстрировали худшие результаты и чаще сдавались, чем те, кто никогда не пользовался ИИ».
...
Для проведения исследования ученые набрали группу из примерно 350 американцев, которым было предложено решить небольшую серию задач с дробями. Чуть более половины участников были случайным образом отнесены к группе, имевшей доступ к чат-боту — специализированному боту, созданному на базе GPT-5 от OpenAI и снабженному конкретными ответами на каждый вопрос этого небольшого теста, — для получения помощи. Остальные участники были отнесены к контрольной группе, не имевшей доступа к ИИ.
Как показали результаты, поначалу чат-бот оказался весьма полезным, помогая участникам, пользовавшимся ИИ, с легкостью пройти тест. Однако в середине короткого экзамена доступ к ИИ внезапно блокировался, и в этот момент способность участников решать задачи на логическое мышление без помощи ИИ резко снижалась, как и их желание продолжать работать над задачей, когда дело доходило до сложных моментов.
Для последующего эксперимента исследователи набрали еще одну, более многочисленную группу из почти 670 участников. Их вновь разделили на две примерно равные половины и попросили выполнить краткий тест на математическое мышление; одной группе предоставили доступ к чат-боту-помощнику — но вновь их ИИ-помощник внезапно «бросил» их, оставив решать задачи самостоятельно. Результаты оказались практически такими же: показатели снизились, как и упорство.
Эти же результаты вновь подтвердились в заключительном эксперименте, в ходе которого количество участников увеличили примерно на 200 человек и попросили их ответить на краткую серию вопросов по пониманию прочитанного, что свидетельствует о том, что подобные результаты не ограничиваются лишь математическими задачами.
«У людей снижается настойчивость», — заявил в интервью Futurism доцент Калифорнийского университета в Лос-Анджелесе Рачит Дубей, специалист в области вычислительной когнитивной науки, который стал соавтором исследования вместе с коллегами из Массачусетского технологического института, Университета Карнеги-Меллона и Оксфордского университета. «Когда у людей забирают ИИ, дело не только в том, что они начинают давать неправильные ответы. Они также не хотят пытаться решать задачи без помощи ИИ».
Исследователи провели сканирование мозга пользователей ChatGPT и обнаружили нечто крайне тревожное
20 июня 2025
futurism.com
Ученые из Массачусетского технологического института обнаружили удивительные результаты при сканировании мозга пользователей ChatGPT, что стало еще одним свидетельством растущего числа данных, указывающих на то, что искусственный интеллект оказывает серьезное — и пока еще малоизученное — влияние на когнитивные процессы своих пользователей, несмотря на стремительный рост его популярности во всем мире.
В новой статье, которая в настоящее время находится на рассмотрении экспертов, исследователи из знаменитой лаборатории Media Lab этого института зафиксировали значительные различия в мозговой активности людей, использующих ChatGPT для написания текстов, и тех, кто им не пользуется.
Исследовательская группа набрала 54 взрослых в возрасте от 18 до 39 лет и разделила их на три группы: одна использовала ChatGPT для помощи в написании эссе, вторая — поиск Google в качестве основного средства помощи при написании, а третья не использовала технологии искусственного интеллекта. Исследование длилось четыре месяца: в течение первых трех месяцев каждая группа должна была писать по одному эссе в месяц, а в четвертый месяц небольшая часть участников либо перешла от отказа от ChatGPT к его использованию, либо наоборот.
Во время выполнения заданий по написанию эссе участники были подключены к аппаратам электроэнцефалографии (ЭЭГ), которые регистрировали их мозговую активность. И вот тут дело принимает неожиданный оборот: группа ChatGPT не только «постоянно показывала худшие результаты на нейронном, лингвистическом и поведенческом уровнях», но и становилась все ленивее с каждым написанным эссе; ЭЭГ выявила «более слабую нейронную связь и недостаточную активность альфа- и бета-сетей». Группа, пользовавшаяся помощью Google, тем временем демонстрировала «умеренную» нейронную активность, в то время как группа, полагавшаяся исключительно на свой мозг, на протяжении всего эксперимента показывала самые высокие когнитивные показатели.
Использование ChatGPT связано с ухудшением памяти и склонностью к прокрастинации у студентов
26 мая 2024
futurism.com
Как подробно описано в новом исследовании, опубликованном в журнале «International Journal of Educational Technology in Higher Education», исследователи провели опрос среди сотен студентов вузов — от бакалавров до аспирантов — в два этапа, используя самооценки респондентов. Их подтолкнуло то, что они стали наблюдать, как все больше и больше их собственных студентов обращаются к ChatGPT.
На первом этапе исследователи собрали ответы 165 студентов, которые с помощью шкалы из восьми пунктов оценили степень своей зависимости от ChatGPT. Пункты варьировались от «Я использую ChatGPT для выполнения курсовых заданий» до «ChatGPT — неотъемлемая часть моей студенческой жизни».
Чтобы подтвердить эти результаты, они также провели более тщательный второй этап исследования с «отсрочкой во времени», в ходе которого охватили почти 500 студентов, которых опрашивали три раза с интервалом в одну-две недели.
Пожалуй, неудивительно, что исследователи обнаружили: студенты, испытывающие высокую учебную нагрузку и «нехватку времени», гораздо чаще прибегали к помощи ChatGPT. Они заметили, что те, кто полагался на ChatGPT, чаще откладывали дела на потом, страдали от ухудшения памяти и снижения среднего балла. Причина этого довольно проста: чат-бот, независимо от качества его ответов, слишком облегчает выполнение учебных заданий.
«Поскольку ChatGPT может быстро отвечать на любые вопросы пользователя, — пишут исследователи в своей работе, — студенты, чрезмерно использующие ChatGPT, могут снизить уровень когнитивных усилий, необходимых для выполнения учебных заданий, что приводит к ухудшению памяти».
Исследование показало, что люди, которые доверяют выполнение задач искусственному интеллекту, теряют навыки критического мышления
11 февраля 2025
futurism.com
Как отмечают ребята из 404 Media, новое исследование Карнеги-Меллона и Microsoft — да, той самой компании, которая инвестировала почти 14 миллиардов долларов в OpenAI и фактически субсидирует разработчика ChatGPT — предполагает, что чем больше люди используют ИИ, тем меньше они используют критическое мышление.
Исследовательская группа опросила 319 «работников умственного труда» — то есть людей, чья работа заключается в решении задач, хотя определения могут различаться — об их опыте использования продуктов на базе генеративного ИИ на рабочем месте.
Результаты этих исследований оказались поразительными: в целом те, кто доверял точности инструментов ИИ, проявляли меньше критического мышления, в то время как те, кто меньше доверял этой технологии, более критично подходили к анализу результатов работы ИИ.
«Данные свидетельствуют о смене характера когнитивной нагрузки: при использовании GenAI специалисты все чаще переключаются с выполнения задач на их контроль», — пишут исследователи. «Удивительно, но хотя ИИ может повысить эффективность, он также может снизить степень вовлеченности в процесс, особенно при выполнении рутинных задач или задач с низкой степенью риска, в которых пользователи просто полагаются на ИИ, что вызывает опасения по поводу долгосрочной зависимости от ИИ и утраты навыков самостоятельного решения проблем».
...
Исследователи обнаружили, что использование ИИ, по-видимому, также сдерживает творческий потенциал: сотрудники, использующие инструменты ИИ, демонстрируют «менее вариативные результаты при выполнении одной и той же задачи» по сравнению с теми, кто полагается на собственные когнитивные способности.
Эксперты обеспокоены тем, что искусственный интеллект делает нас глупее
27 апреля 2025
futurism.com
Искусственный интеллект, возможно, постепенно проникает во все сферы нашей жизни, но это не значит, что он делает нас умнее.
Совсем наоборот. В новом анализе недавних исследований, опубликованном в газете «The Guardian», рассматривается потенциальная ирония ситуации: не теряем ли мы больше, чем получаем, втискивая ИИ в нашу повседневную работу и перекладывая на него столько интеллектуальных задач, что это подрывает наши собственные когнитивные способности.
В этом анализе упоминается ряд исследований, которые указывают на связь между снижением когнитивных способностей и использованием инструментов искусственного интеллекта, особенно в сфере критического мышления. В одной научной статье, опубликованной в журнале Frontiers in Psychology — и сама статья пропущена через ChatGPT для внесения «исправлений», согласно предупреждению, которое мы не могли не заметить — говорится о том, что регулярное использование ИИ может привести к атрофии наших реальных когнитивных способностей и объема памяти.
Еще одно исследование, проведенное Майклом Герлихом из Швейцарской бизнес-школы и опубликованное в журнале «Societies», указывает на связь между «частым использованием инструментов ИИ и способностями к критическому мышлению», подчеркивая то, что Герлих называет «когнитивными издержками зависимости от инструментов ИИ».
Исследователь приводит пример применения ИИ в сфере здравоохранения, где автоматизированные системы повышают эффективность работы больниц за счет сокращения штата штатных специалистов, чья работа заключается в «проведении самостоятельного критического анализа» — иными словами, в принятии решений, требующих человеческого участия.
Все это не так неправдоподобно, как может показаться. Множество исследований показали, что умственные способности — это ресурс, который нужно «использовать или потерять», поэтому вполне логично, что обращение к ChatGPT для решения повседневных задач, таких как написание сложных писем, проведение исследований или решение проблем, может привести к негативным результатам.
По мере того как люди перекладывают все более сложные задачи на различные модели ИИ, мы также становимся склонны воспринимать ИИ как «волшебную палочку» — универсальное средство, способное взять на себя всю тяжелую работу по размышлениям за нас. Такое отношение активно продвигается индустрией ИИ, которая использует смесь модных технических терминов и маркетингового ажиотажа, чтобы продать нам такие идеи, как «глубокое обучение», «рассуждения» и «общий искусственный интеллект».
В частности, еще одно недавнее исследование показало, что четверть представителей поколения Z считают, что ИИ «уже обладает сознанием». Сбор тысяч общедоступных данных за считанные секунды позволяет чат-ботам с ИИ выдавать, казалось бы, вдумчивые тексты, что, безусловно, создает впечатление человекоподобного сознания. Но именно такое отношение, как предупреждают эксперты, ведет нас по темному пути.
«Критически относиться к ИИ непросто — для этого нужна самодисциплина», — говорит Герлих. «Очень сложно не переложить свое критическое мышление на эти машины».
У детей, которые используют ChatGPT в качестве помощника в учебе, результаты тестов хуже
2 сентября 2024
hechingerreport.org
Исследователи из Пенсильванского университета обнаружили, что турецкие старшеклассники, у которых был доступ к ChatGPT во время решения тренировочных задач по математике, показали более низкие результаты на тесте по математике по сравнению с теми, у кого такого доступа не было. Учащиеся, пользовавшиеся ChatGPT, правильно решили на 48 % больше тренировочных задач, но в итоге набрали на 17 % меньше баллов на тесте по изучаемой теме.
Третья группа студентов имела доступ к модифицированной версии ChatGPT, которая работала скорее как репетитор. Этот чат-бот был запрограммирован так, чтобы давать подсказки, не раскрывая при этом самого ответа. Студенты, которые пользовались им, показали значительно лучшие результаты при решении тренировочных задач: они правильно решили на 127 процентов больше задач по сравнению со студентами, выполнявшими упражнения без каких-либо высокотехнологичных средств. Однако на последующем тесте эти студенты, занимавшиеся с помощью ИИ, не показали лучших результатов. Студенты, которые просто решали практические задачи по-старинке — самостоятельно — показали такие же результаты на тесте.
Исследователи назвали свою статью «Генеративный ИИ может нанести вред обучению», чтобы донести до родителей и педагогов, что современные общедоступные чат-боты на базе ИИ могут «существенно затруднять процесс обучения». Даже специально настроенная версия ChatGPT, призванная имитировать репетитора, не всегда оказывается полезной.
Ошибки моделей ИИ
Галлюцинации / Ложные ответы
Статистика галлюцинаций ИИ: исследовательский отчет 2026 года
15 февраля, 2026
suprmind.ai
Цифры просто ошеломляют:
- Только в 2024 году убытки мирового бизнеса, вызванные «галлюцинациями» ИИ, составили 67,4 млрд долларов
- 47 % руководителей компаний принимали важные решения на основе непроверенной информации, сгенерированной искусственным интеллектом
- Даже самые совершенные модели искусственного интеллекта по-прежнему дают неверные ответы как минимум в 0,7 % случаев при решении простых задач по обобщению информации, а этот показатель резко возрастает до 18,7 % при ответе на юридические вопросы и до 15,6 % при ответе на медицинские запросы
- При решении сложных вопросов, требующих знаний, все модели, за исключением трёх из 40 протестированных, чаще дают неверные ответы, чем правильные
Тест 1: Лидеры галлюцинаций по версии Vectara (HHEM)
Что измеряется
Vectara Hughes Hallucination Evaluation Model (HHEM) — это наиболее авторитетный в отрасли тест на галлюцинации. Он измеряет галлюцинации по основанию — то, как часто большая языковая модель (LLM) вводит ложную информацию при составлении резюме документа, который ей явно предоставили. Можно представить это так: «Способна ли модель придерживаться того, что написано перед ней?»
Методология: каждой модели предоставляется более 1000 документов с указанием подготовить резюме, используя только факты, содержащиеся в этих документах. Затем модель HHEM компании Vectara сравнивает каждое резюме с исходным текстом, чтобы выявить вымышленные утверждения.
Частота галлюцинаций - исходный набор данных (Апрель 2025)
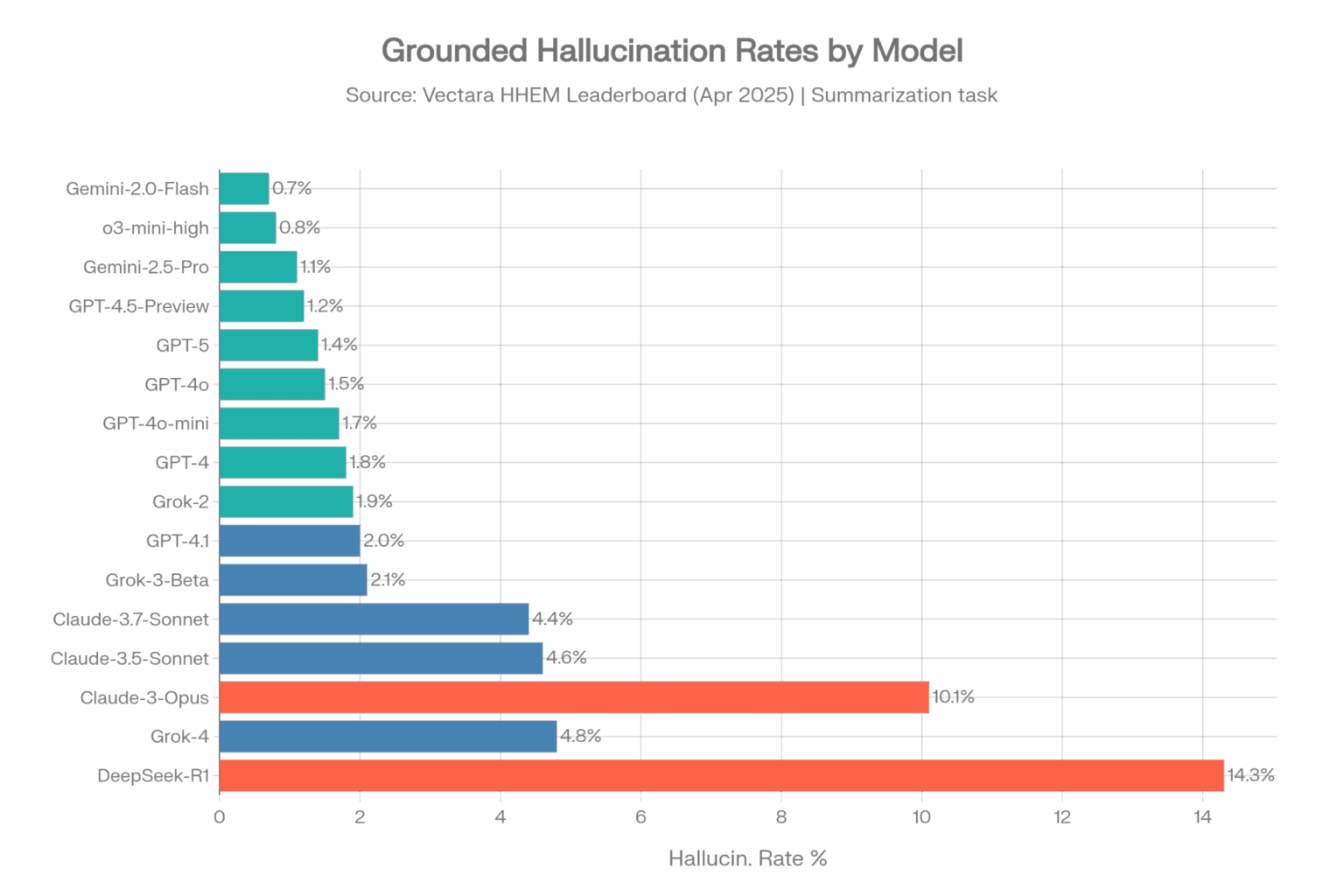
Доля галлюцинаций / ложных ответов, %
Данные в таблице:
| Модель | Поставщик | Доля галлюцинаций | Фактическая согласованность |
|---|---|---|---|
| Gemini-2.0-Flash-001 | 0.7% | 99.3% | |
| Gemini-2.0-Pro-Exp | 0.8% | 99.2% | |
| o3-mini-high | OpenAI | 0.8% | 99.2% |
| Gemini-2.5-Pro-Exp | 1.1% | 98.9% | |
| GPT-4.5-Preview | OpenAI | 1.2% | 98.8% |
| Gemini-2.5-Flash-Preview | 1.3% | 98.7% | |
| o1-mini | OpenAI | 1.4% | 98.6% |
| GPT-5 / ChatGPT-5 | OpenAI | 1.4% | 98.6% |
| GPT-4o | OpenAI | 1.5% | 98.5% |
| GPT-4o-mini | OpenAI | 1.7% | 98.3% |
| GPT-4-Turbo | OpenAI | 1.7% | 98.3% |
| GPT-4 | OpenAI | 1.8% | 98.2% |
| Grok-2 | xAI | 1.9% | 98.1% |
| GPT-4.1 | OpenAI | 2.0% | 98.0% |
| Grok-3-Beta | xAI | 2.1% | 97.8% |
| Claude-3.7-Sonnet | Anthropic | 4.4% | 95.6% |
| Claude-3.5-Sonnet | Anthropic | 4.6% | 95.4% |
| Claude-3.5-Haiku | Anthropic | 4.9% | 95.1% |
| Grok-4 | xAI | 4.8% | ~95.2% |
| Llama-4-Maverick | Meta | 4.6% | 95.4% |
| Claude-3-Opus | Anthropic | 10.1% | 89.9% |
| DeepSeek-R1 | DeepSeek | 14.3% | 85.7% |
| Источник: Vectara HHEM Leaderboard, GitHub, Апрель 2025 |
Частота галлюцинаций - Новый набор данных (Ноябрь 2025 - Февраль 2026)
В конце 2025 года компания Vectara представила полностью обновленный набор данных для тестирования, включающий 7 700 статей (по сравнению с 1 000 ранее), более объемные документы (до 32 000 токенов) и контент повышенной сложности из таких областей, как право, медицина, финансы, технологии и образование.
Показатели значительно выше — это сделано специально. Этот тест лучше отражает реальные рабочие нагрузки в корпоративной среде.
| Модель | Поставщик | Доля галлюцинаций |
|---|---|---|
| Gemini-2.5-Flash-Lite | 3.3% | |
| Mistral-Large | Mistral | 4.5% |
| DeepSeek-V3.2-Exp | DeepSeek | 5.3% |
| GPT-4.1 | OpenAI | 5.6% |
| Grok-3 | xAI | 5.8% |
| DeepSeek-R1-0528 | DeepSeek | 7.7% |
| Claude Sonnet 4.5 | Anthropic | >10% |
| GPT-5 | OpenAI | >10% |
| Grok-4 | xAI | >10% |
| Gemini-3-Pro | 13.6% | |
| Источник: Vectara Hallucination Leaderboard, новый набор данных, Ноябрь 2025 |
Обновленный тест Vectara выявил важный факт: модели, ориентированные на логическое мышление, на самом деле демонстрируют худшие результаты при составлении обобщений на основе фактических документов. Такие модели, как GPT-5, Claude Sonnet 4.5, Grok-4 и Gemini-3-Pro, которые позиционируются как мощные «логические системы», все показали уровень галлюцинаций свыше 10 % в более сложном тесте.
Тест 2: AA-Omniscience (Анализ ИИ - Всеведение)
AA-Omniscience показывает, что все модели, за исключением трёх, при получении сложного вопроса с большей вероятностью выдают неверный ответ, чем дают правильный.
Подробная информация об AA-Omniscience:
🔢 6 000 вопросов по 42 темам в 6 областях («Бизнес», «Гуманитарные и социальные науки», «Здравоохранение», «Право», «Программная инженерия» и «Естественные науки, инженерия и математика»)
🔍 89 подтем, включая библиотеки данных Python, государственную политику, налогообложение и многое другое, что дает более четкое представление о том, в каких областях модели преуспевают, а в каких испытывают трудности
🔄 Неправильные ответы штрафуются в нашей системе подсчета индекса надежности знаний, чтобы наказывать модели за галлюцинации
📊 3 показателя: точность (% правильных ответов), частота галлюцинаций (% неправильных ответов из общего числа неправильных ответов и воздержаний от ответа), индекс AA-Omniscience (+1 за правильный ответ, -1 за неправильный ответ, если ответ был дан, 0 за воздержание, если модель не пыталась ответить)
| Модель | Точность (доля правильных ответов) |
Доля ложных ответов среди всех неудачных попыток | Индекс Omniscience |
|---|---|---|---|
| Grok 4 | 39% | 64% | 1 |
| GPT-5 (high) | 39% | 81% | -11 |
| Gemini 2.5 Pro | 37% | 89% | -18 |
| Claude 4.1 Opus | 36% | 48% | 5 |
| GPT-5.1 (high) | 35% | 51% | 2 |
| Claude 4.5 Sonnet | 31% | 48% | -2 |
| Deepseek R1 0528 | 29% | 83% | -30 |
| Kimi K2 Thinking | 29% | 74% | -23 |
| Deepseek V3.1 Terminus | 27% | 74% | |
| Gemini 2.5 Flash (Sep) | 27% | 88% | -38 |
| DeepSeek V3.2 Exp | 27% | 80% | -32 |
| GPT-4.1 | 26% | 92% | |
| GLM 4.6 | 25% | 93% | -44 |
| Kimi K2 0905 | 24% | 69% | -28 |
| Llama 4 Maverick | 23% | 88% | -44 |
| GPT-5 mini (high) | 23% | 55% | -37 |
| Grok 4 Fast | 22% | 67% | -30 |
| Llama 3.1 405B | 22% | 51% |
Источник: https://artificialanalysis.ai/articles/aa-omniscience-knowledge-hallucination-benchmark
*Актуальные данные - https://artificialanalysis.ai/evaluations/omniscience
Улучшаются или ухудшаются галлюцинации ИИ? Мы проанализировали данные
7 января 2026
scottfraffius.com
В 2025 году показатели частоты галлюцинаций резко различались в зависимости от того, какие задачи ставились перед моделями.
В тестах, позволяющих сравнивать модели на равных условиях, таких как рейтинг Vectara по суммированию текста, производительность улучшилась по всем направлениям. Уровень галлюцинаций у нескольких ведущих моделей опустился ниже 1%, в том числе у Gemini-2.0-Flash от Google (около 0,7%), а варианты OpenAI и Gemini показали результаты в диапазоне 0,8–1,5% (Vectara, 2025; AllAboutAI, 2025). При выполнении задач с привязкой к источнику — когда модель может соотносить свой вывод с исходным документом — частота галлюцинаций со временем снижается.
Однако более новые модели, ориентированные на логическое мышление, демонстрируют иную картину. Системы, оптимизированные для сложного логического мышления с цепочкой рассуждений, чаще демонстрируют галлюцинации на тестах с открытыми вопросами, требующих проверки фактов. Например, у моделей серии o3 от OpenAI частота неверных ответов на тестах PersonQA и SimpleQA составила 33–51 %. Это более чем в два раза превышает показатели более ранних моделей серии o1, которые колебались около 16% (OpenAI, 2025; Techopedia, 2025). Расширенные оценки 2025 года отражают этот сдвиг. В наборах задач, содержащих как простые, так и сложные случаи, частота галлюцинаций обычно составляет 3–20% или выше (Stanford HAI, 2025).
По сопоставимым показателям частота галлюцинаций в несложных задачах снижается из года в год. В задачах по обобщению заданного текста показатели лучших моделей снизились с примерно 1–3 % в 2024 году до 0,7–1,5 % в 2025 году. Однако частота галлюцинаций по-прежнему остается высокой в задачах, требующих сложного логического мышления и воспроизведения фактов из открытых источников, где этот показатель может превышать 33 %.
Галлюцинации ИИ: сравнение ведущих моделей LLM (больших языковых моделей), таких как GPT-5.2
23 января 2026
aimultiple.com
Мы провели сравнительный анализ 37 различных моделей ИИ с помощью 60 вопросов, чтобы оценить частоту появления галлюцинаций:
Частота галлюцианций (доля ложных ответов):
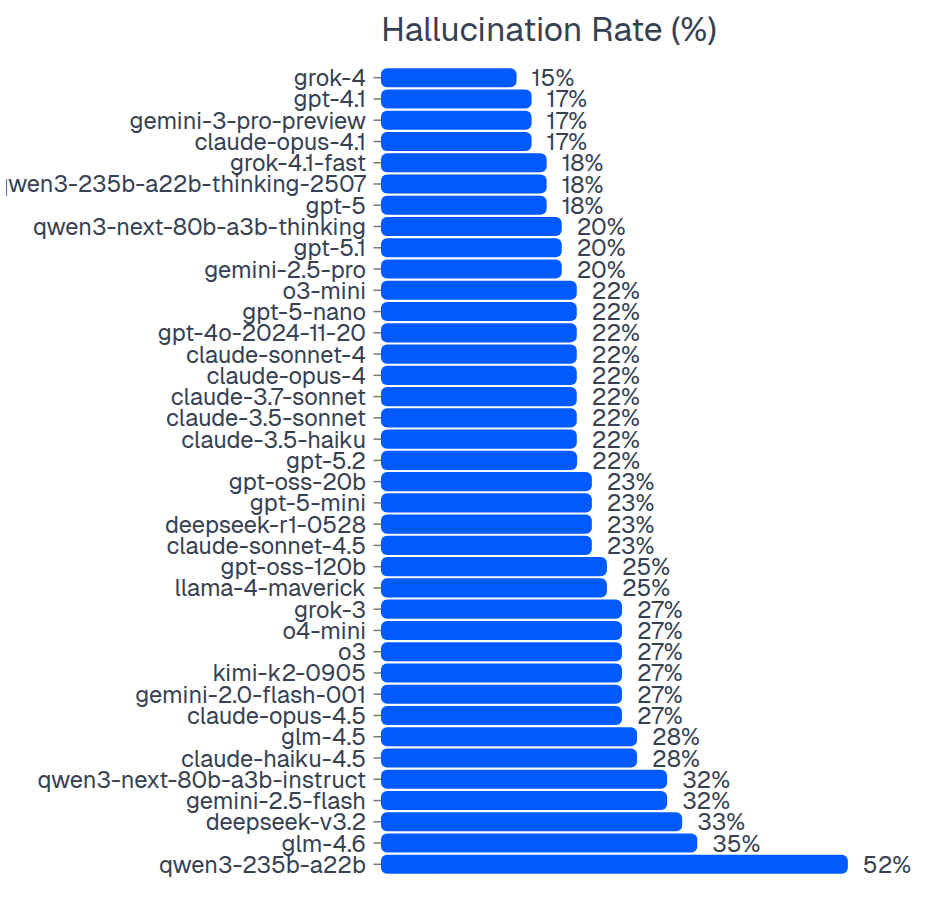
Наше тестирование показало, что даже у самых последних моделей уровень ошибок при анализе предоставленных утверждений превышает 15%. Ознакомьтесь с методикой тестирования, чтобы узнать, как мы измеряли эти показатели.
Реальность галлюцинаций ИИ в 2025 году
21 июля 2025
drainpipe.io
Что касается хорошо оптимизированных моделей высшего уровня, предназначенных для задач обеспечения фактической достоверности (например, составления резюме коротких документов с фактологическим содержанием):
- Некоторые ведущие модели, такие как Google Gemini-2.0-Flash-001 и определенные варианты OpenAI o3-mini-high, демонстрируют уровень галлюцинаций на уровне всего 0,7–0,9 %. Это означает, что на каждые 100 ответов вы можете встретить менее одного выдуманного ответа.
- В настоящее время существует четыре модели с показателями галлюцинаций ниже 1%, что является важной вехой в обеспечении достоверности.
Для общих задач и распространенных моделей:
- Многие широко используемые модели относятся к «группе со средним уровнем галлюцинаций», где показатели обычно составляют от 2% до 5%. Это означает, что на каждые 100 взаимодействий может приходиться от 2 до 5 галлюцинаций.
- В целом по всем моделям средний показатель галлюцинаций при ответе на вопросы из области общих знаний может составлять около 9,2%.
При решении сложных задач, в специализированных областях или при использовании менее оптимизированных моделей:
- Частота галлюцинаций может значительно возрасти — от 5 % до почти 30 % или даже выше для определенных моделей и типов запросов.
- Риски, связанные с конкретными областями, выше:
- Юридическая информация: средний уровень галлюцинаций может составлять 6,4% даже для лучших моделей и до 18,7% для всех моделей.
- Медицина/здравоохранение: средний уровень может составлять 4,3% для лучших моделей и до 15,6% в целом.
- Финансовые данные: средний показатель может составлять 2,1% для лучших моделей и до 13,8% в целом.
- Научные исследования: средний показатель может составлять 3,7% для лучших моделей и до 16,9% в целом.
- Более новые модели «рассуждения» от некоторых разработчиков даже показали более высокие показатели галлюцинаций на определенных тестах (например, модели o3 и o4-mini от OpenAI показали 33% и 48% галлюцинаций соответственно на тесте «PersonQA» и еще более высокие показатели на тесте «SimpleQA»), что указывает на потенциальный компромисс между продвинутым рассуждением и фактической точностью в некоторых случаях.
«Специалисты, работающие с информацией, тратят 4,3 часа в неделю на проверку результатов работы ИИ». – Отчет о галлюцинациях ИИ за 2025 год: какой ИИ галлюцинирует чаще всего? – AllAboutAI.com (со ссылкой на Microsoft, 2025)
«47 % корпоративных пользователей ИИ приняли по крайней мере одно важное решение на основе вымышленных данных». – Отчет о галлюцинациях ИИ 2025: какой ИИ галлюцинирует чаще всего? – AllAboutAI.com (со ссылкой на Deloitte, 2025)
«В настоящее время 76 % предприятий используют процессы с участием человека для выявления галлюцинаций перед внедрением». – Отчет о галлюцинациях ИИ 2025: какой ИИ галлюцинирует чаще всего? – AllAboutAI.com (со ссылкой на IBM AI Adoption Index, 2025)
Ошибки цитирования
У поиска на базе ИИ есть проблема с цитированием
6 марта 2025
cjr.org
Мы сравнили восемь поисковых систем на базе искусственного интеллекта. Все они плохо справляются с цитированием новостей.
Мы провели систематическое тестирование восьми генеративных поисковых инструментов: ChatGPT Search от OpenAI, Perplexity, Perplexity Pro, DeepSeek Search, Copilot от Microsoft, Grok-2 и Grok-3 (бета-версия) от xAI, а также Gemini от Google.
Мы отобрали 20 новостных изданий, занимающих разные позиции в отношении доступа ИИ, которые либо разрешают веб-сканерам поисковых роботов доступ через файл robots.txt, либо блокируют его.
Мы случайным образом отобрали по десять статей от каждого издателя, а затем вручную выбрали из них прямые цитаты для использования в наших запросах. Предоставив каждому чат-боту выбранные цитаты, мы попросили его определить заголовок соответствующей статьи, исходного издателя, дату публикации и ссылку на источник.
Мы специально выбрали отрывки, при вставке которых в традиционный поиск Google исходный материал появлялся в первых трёх результатах. Всего мы выполнили 1600 запросов (20 издателей умноженные на 10 статей умноженные на 8 чат-ботов). Мы вручную оценивали ответы чат-ботов по трем критериям: нахождение (1) правильной статьи, (2) правильного издателя и (3) правильного URL-адреса. В соответствии с этими параметрами каждый ответ был помечен одной из следующих меток:
- Зеленый - Правильно: все три атрибута указаны правильно.
- Светло-зеленый - Правильно, но неполно: некоторые атрибуты указаны правильно, но в ответе отсутствует часть информации.
- Светло-розовый - Частично неверно: некоторые атрибуты указаны правильно, а другие — нет.
- Розовый - Полностью неверно: все три атрибута указаны неверно и/или отсутствуют.
- Серый - Не указано: информация не предоставлена.
- Крест - Блокировка сканера: издатель запретил доступ сканеру чат-бота в файле robots.txt.
В целом чат-боты зачастую не могли найти нужные статьи. В совокупности они давали неверные ответы более чем на 60 процентов запросов. Уровень неточности варьировался в зависимости от платформы: Perplexity давал неверные ответы на 37 процентов запросов, тогда как у Grok 3 показатель ошибок был значительно выше — неверные ответы давались на 94 процента запросов.
Большинство протестированных нами инструментов давали неточные ответы с пугающей уверенностью, редко используя оговорки, такие как «похоже», «возможно», «может быть» и т. п., или признавая пробелы в знаниях с помощью фраз вроде «я не смог найти нужную статью». Например, ChatGPT неправильно идентифицировал 134 статьи, но из двухсот ответов всего пятнадцать раз указал на отсутствие уверенности и ни разу не отказался дать ответ. За исключением Copilot — который отклонил больше вопросов, чем ответил на них — все инструменты были склонны чаще давать неверный ответ, чем признавать свою ограниченность.
Итоговая таблица:
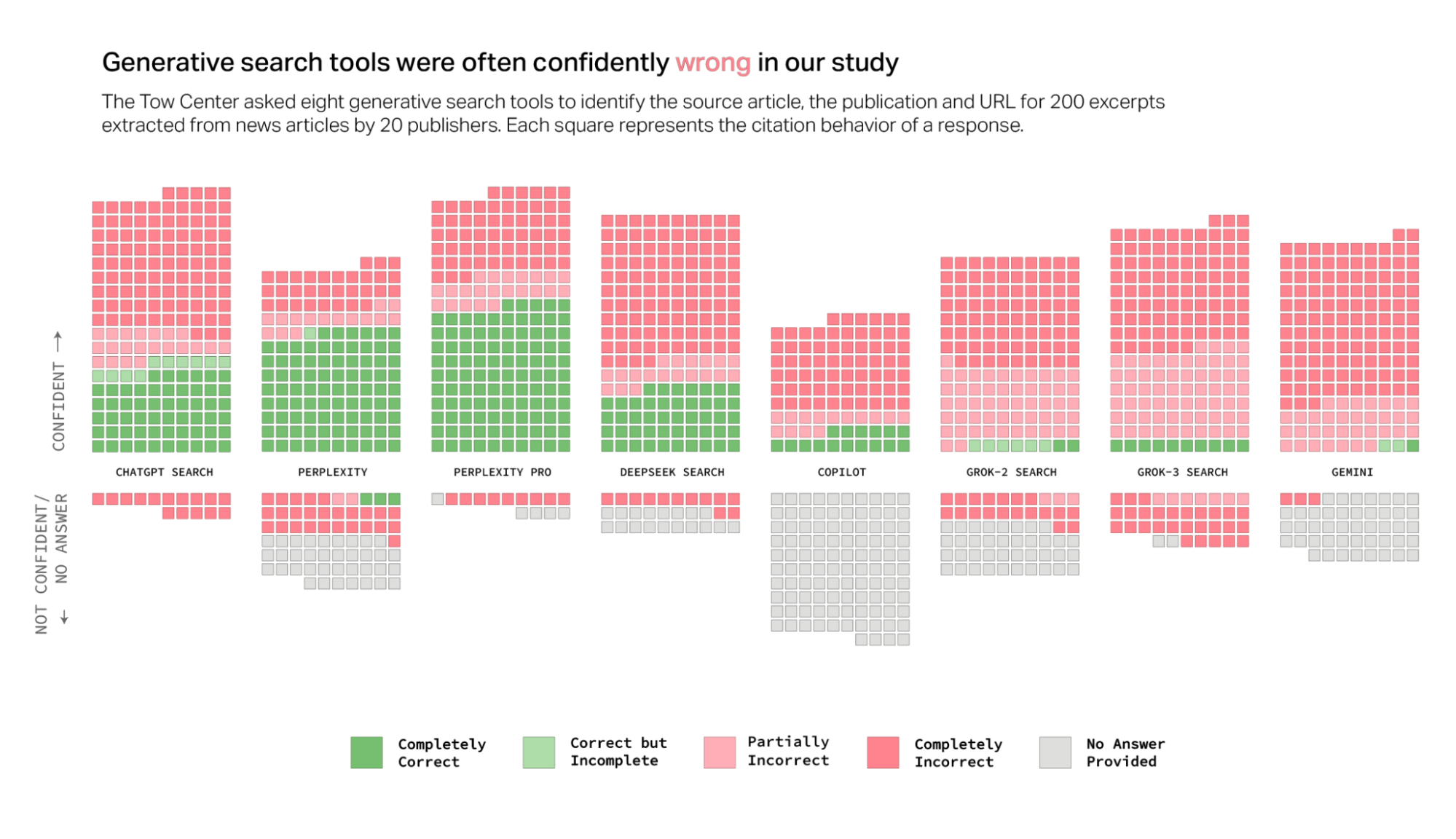
Вверху - уверенные ответы чат-бота. Внизу - неуверенные / без ответа.
Протестированные нами инструменты генеративного поиска демонстрировали общую тенденцию указывать неверные источники статей. Например, DeepSeek в 115 случаях из 200 неправильно указывал источник отрывков, предоставленных в наших запросах. Это означает, что контент новостных изданий чаще всего приписывался не тому источнику.
Даже в тех случаях, когда чат-боты, казалось бы, правильно определяли статью, они зачастую не могли правильно указать ссылку на исходный источник
Более половины ответов, полученных от Gemini и Grok 3, содержали вымышленные или неработающие URL-адреса, которые вели на несуществующий адрес с ошибкой 404.
Итоговая таблица:
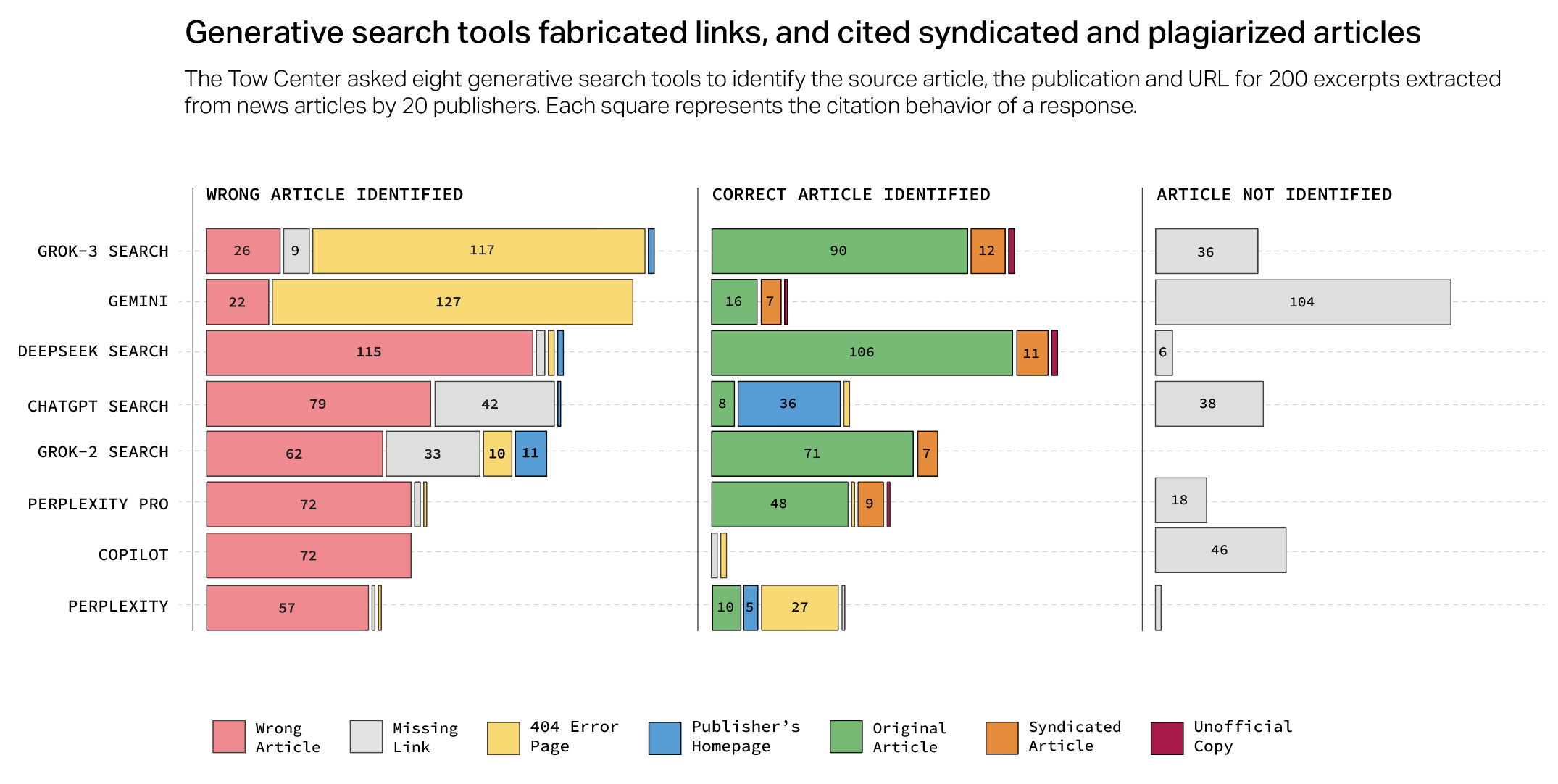
Розовый - неверная статья
Серый - отсутствие ссылки
Желтый - ссылка ведет на несуществующий адрес, ошибка 404
Синий - ссылка ведет на домашнюю страницу издателя
Зеленый - ссылка на оригинальную статью
Оранжевый - ссылка на официальную копию статьи на другом ресурсе, так называемая синдицированная статья, например на Yahoo News
Бордовый - неофициальная копия статьи